Optimization-Based Control
The optimal module contains a set of classes and functions that can
be used to solve optimal control and optimal estimation problems for
linear or nonlinear systems. The objects in this module must be
explicitly imported:
import control as ct
import control.optimal as opt
Optimal control problem setup
Consider the optimal control problem:

subject to the constraint

Abstractly, this is a constrained optimization problem where we seek a
feasible trajectory  that minimizes the cost function
that minimizes the cost function

More formally, this problem is equivalent to the “standard” problem of
minimizing a cost function  where
where ![(x, u) \in L_2[0,T]](_images/math/f10b6c8e8a97041d31669bcbcd9f55c736202bfa.png) (the set of square integrable functions) and
(the set of square integrable functions) and  models the dynamics. The term
models the dynamics. The term  is
referred to as the integral (or trajectory) cost and
is
referred to as the integral (or trajectory) cost and  is the
final (or terminal) cost.
is the
final (or terminal) cost.
It is often convenient to ask that the final value of the trajectory,
denoted  , be specified. We can do this by requiring that
, be specified. We can do this by requiring that
 or by using a more general form of constraint:
or by using a more general form of constraint:

The fully constrained case is obtained by setting  and defining
and defining
 . For a control problem with
a full set of terminal constraints, can be omitted (since
its value is fixed).
. For a control problem with
a full set of terminal constraints, can be omitted (since
its value is fixed).
Finally, we may wish to consider optimizations in which either the state or the inputs are constrained by a set of nonlinear functions of the form

where  and
and  represent lower and upper
bounds on the constraint function
represent lower and upper
bounds on the constraint function  . Note that these constraints
can be on the input, the state, or combinations of input and state,
depending on the form of . Furthermore, these constraints are
intended to hold at all instants in time along the trajectory.
. Note that these constraints
can be on the input, the state, or combinations of input and state,
depending on the form of . Furthermore, these constraints are
intended to hold at all instants in time along the trajectory.
For a discrete-time system, the same basic formulation applies except that the cost function is given by

A common use of optimization-based control techniques is the implementation of model predictive control (MPC, also called receding horizon control). In model predictive control, a finite horizon optimal control problem is solved, generating open-loop state and control trajectories. The resulting control trajectory is applied to the system for a fraction of the horizon length. This process is then repeated, resulting in a sampled data feedback law. This approach is illustrated in the following figure:
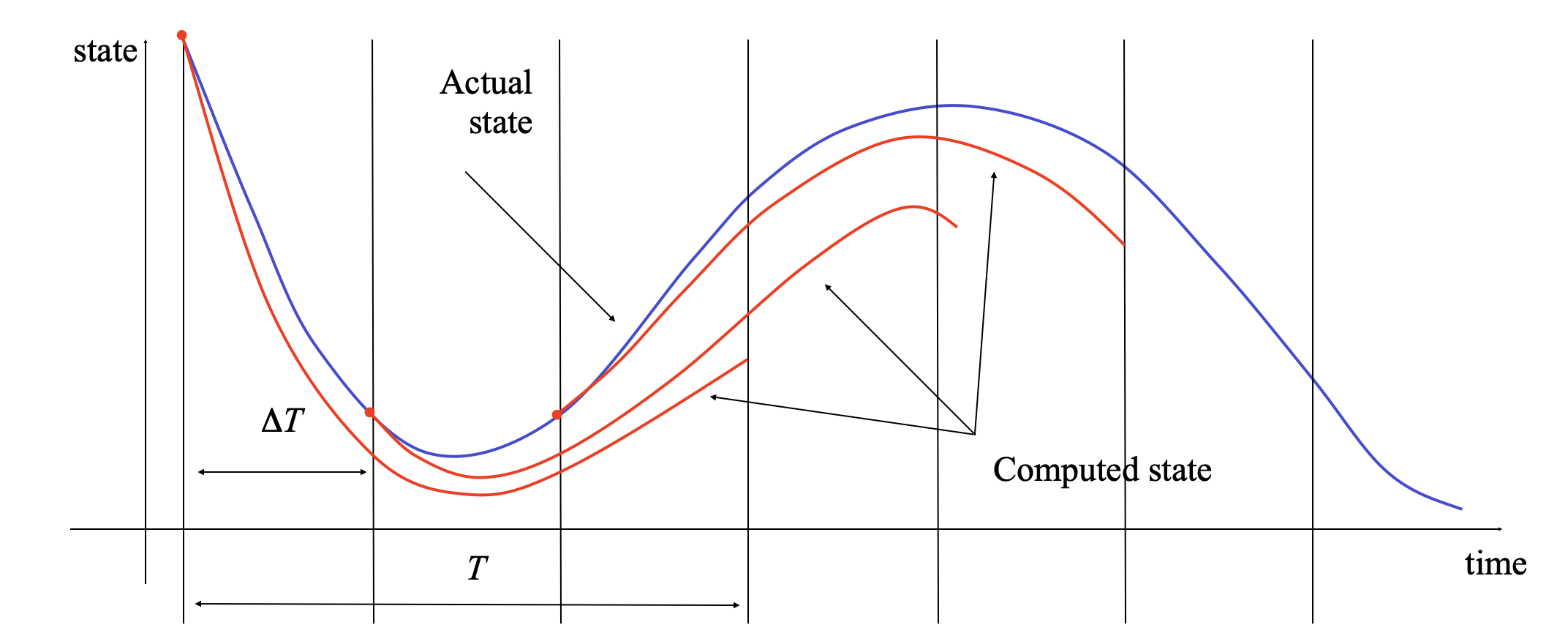
Every  seconds, an optimal control problem is solved over a
seconds, an optimal control problem is solved over a
 second horizon, starting from the current state. The first
seconds of the optimal control
second horizon, starting from the current state. The first
seconds of the optimal control  is then applied to the system. If we let
is then applied to the system. If we let  represent the optimal trajectory starting from
represent the optimal trajectory starting from  then the
system state evolves from at current time
then the
system state evolves from at current time  to
to
 at the next sample time
at the next sample time  , assuming no model uncertainty.
, assuming no model uncertainty.
In reality, the system will not follow the predicted path exactly, so that
the red (computed) and blue (actual) trajectories will diverge. We thus
recompute the optimal path from the new state at time  ,
extending our horizon by an additional units of time. This
approach can be shown to generate stabilizing control laws under suitable
conditions (see, for example, the FBS2e supplement on Optimization-Based
Control).
,
extending our horizon by an additional units of time. This
approach can be shown to generate stabilizing control laws under suitable
conditions (see, for example, the FBS2e supplement on Optimization-Based
Control).
Module usage
The optimization-based control module provides a means of computing
optimal trajectories for nonlinear systems and implementing
optimization-based controllers, including model predictive control.
It follows the basic problem setups described above, but carries out
all computations in discrete time (so that integrals become sums)
and over a finite horizon. To access the optimal control modules,
import control.optimal:
import control.optimal as opt
To describe an optimal control problem we need an input/output system, a
time horizon, a cost function, and (optionally) a set of constraints on the
state and/or input, along the trajectory and/or at the terminal time.
The optimal control module operates by converting the optimal control
problem into a standard optimization problem that can be solved by
scipy.optimize.minimize(). The optimal control problem can be solved
by using the solve_optimal_trajectory() function:
res = opt.solve_optimal_trajectory(sys, timepts, X0, cost, constraints)
The sys parameter should be an InputOutputSystem and the
timepts parameter should represent a time vector that gives the list
of times at which the cost and constraints should be evaluated (the
time points need not be uniformly spaced).
The cost function has call signature cost(t, x, u) and should
return the (incremental) cost at the given time, state, and input. It
will be evaluated at each point in the timepts vector. The
terminal_cost parameter can be used to specify a cost function for
the final point in the trajectory.
The constraints parameter is a list of constraints similar to that
used by the scipy.optimize.minimize() function. Each constraint
is specified using one of the following forms:
LinearConstraint(A, lb, ub)
NonlinearConstraint(f, lb, ub)
For a linear constraint, the 2D array A is multiplied by a vector
consisting of the current state x and current input u stacked
vertically, then compared with the upper and lower bound. This constraint
is satisfied if
lb <= A @ np.hstack([x, u]) <= ub
A nonlinear constraint is satisfied if
lb <= f(x, u) <= ub
The constraints are taken as trajectory constraints holding at all
points on the trajectory. The terminal_constraints parameter can be
used to specify a constraint that only holds at the final point of the
trajectory.
The return value for solve_optimal_trajectory() is a
bundle object that has the following elements:
res.success: True if the optimization was successfully solved
res.inputs: optimal input
res.states: state trajectory (ifreturn_xwas True)
res.time: copy of the timetimeptsvector
In addition, the results from scipy.optimize.minimize() are also
available as additional attributes, as described in
scipy.optimize.OptimizeResult.
To simplify the specification of cost functions and constraints, the
optimal module defines a number of utility functions for
optimal control problems:
|
Create quadratic cost function. |
|
Create input constraint from polytope. |
|
Create input constraint from polytope. |
|
Create output constraint from polytope. |
|
Create output constraint from range. |
|
Create state constraint from polytope. |
|
Create state constraint from range. |
Example
Consider the vehicle steering example described in Example 2.3 of Optimization-Based Control (OBC). The dynamics of the system can be defined as a nonlinear input/output system using the following code:
import matplotlib.pyplot as plt
import numpy as np
import control as ct
import control.optimal as opt
def vehicle_update(t, x, u, params):
# Get the parameters for the model
l = params.get('wheelbase', 3.) # vehicle wheelbase
phimax = params.get('maxsteer', 0.5) # max steering angle (rad)
# Saturate the steering input
phi = np.clip(u[1], -phimax, phimax)
# Return the derivative of the state
return np.array([
np.cos(x[2]) * u[0], # xdot = cos(theta) v
np.sin(x[2]) * u[0], # ydot = sin(theta) v
(u[0] / l) * np.tan(phi) # thdot = v/l tan(phi)
])
def vehicle_output(t, x, u, params):
return x # return x, y, theta (full state)
# Define the vehicle steering dynamics as an input/output system
vehicle = ct.NonlinearIOSystem(
vehicle_update, vehicle_output, states=3, name='vehicle',
inputs=('v', 'phi'), outputs=('x', 'y', 'theta'))
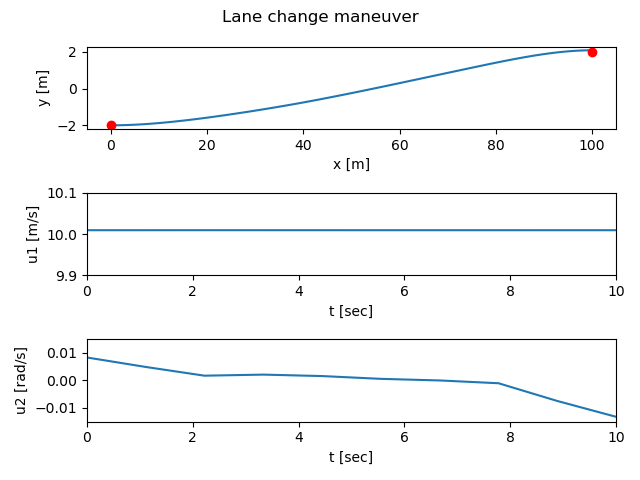
We consider an optimal control problem that consists of “changing lanes” by
moving from the point x = 0 m, y = -2 m,  = 0 to the point x =
100 m, y = 2 m, = 0) over a period of 10 seconds and
with a starting and ending velocity of 10 m/s:
= 0 to the point x =
100 m, y = 2 m, = 0) over a period of 10 seconds and
with a starting and ending velocity of 10 m/s:
x0 = np.array([0., -2., 0.]); u0 = np.array([10., 0.])
xf = np.array([100., 2., 0.]); uf = np.array([10., 0.])
Tf = 10
To set up the optimal control problem we design a cost function that penalizes the state and input using quadratic cost functions:
Q = np.diag([0, 0, 0.1]) # don't turn too sharply
R = np.diag([1, 1]) # keep inputs small
P = np.diag([1000, 1000, 1000]) # get close to final point
traj_cost = opt.quadratic_cost(vehicle, Q, R, x0=xf, u0=uf)
term_cost = opt.quadratic_cost(vehicle, P, 0, x0=xf)
We also constrain the maximum turning rate to 0.1 radians (about 6 degrees) and constrain the velocity to be in the range of 9 m/s to 11 m/s:
constraints = [ opt.input_range_constraint(vehicle, [8, -0.1], [12, 0.1]) ]
Finally, we solve for the optimal inputs:
timepts = np.linspace(0, Tf, 10, endpoint=True)
result = opt.solve_optimal_trajectory(
vehicle, timepts, x0, traj_cost, constraints,
terminal_cost=term_cost, initial_guess=u0)
Plotting the results:
# Simulate the system dynamics (open loop)
resp = ct.input_output_response(
vehicle, timepts, result.inputs, x0,
evaluation_times=np.linspace(0, Tf, 100))
t, y, u = resp.time, resp.outputs, resp.inputs
plt.subplot(3, 1, 1)
plt.plot(y[0], y[1])
plt.plot(x0[0], x0[1], 'ro', xf[0], xf[1], 'ro')
plt.xlabel("x [m]")
plt.ylabel("y [m]")
plt.subplot(3, 1, 2)
plt.plot(t, u[0])
plt.axis([0, 10, 9.9, 10.1])
plt.xlabel("t [sec]")
plt.ylabel("u1 [m/s]")
plt.subplot(3, 1, 3)
plt.plot(t, u[1])
plt.axis([0, 10, -0.015, 0.015])
plt.xlabel("t [sec]")
plt.ylabel("u2 [rad/s]")
plt.suptitle("Lane change maneuver")
plt.tight_layout()
yields
Optimization Tips
The python-control optimization module makes use of the SciPy optimization toolbox and it can sometimes be tricky to get the optimization to converge. If you are getting errors when solving optimal control problems or your solutions do not seem close to optimal, here are a few things to try:
The initial guess matters: providing a reasonable initial guess is often needed in order for the optimizer to find a good answer. For an optimal control problem that uses a larger terminal cost to get to a neighborhood of a final point, a straight line in the state space often works well.
Less is more: try using a smaller number of time points in your optimization. The default optimal control problem formulation uses the value of the inputs at each time point as a free variable and this can generate a large number of parameters quickly. Often you can find very good solutions with a small number of free variables (the example above uses 3 time points for 2 inputs, so a total of 6 optimization variables). Note that you can “resample” the optimal trajectory by running a simulation of the system and using the
t_evalkeyword ininput_output_response(as done above).Use a smooth basis: as an alternative to parameterizing the optimal control inputs using the value of the control at the listed time points, you can specify a set of basis functions using the
basiskeyword insolve_optimal_trajectory()and then parameterize the controller by linear combination of the basis functions. The flatsys subpackage defines several sets of basis functions that can be used.Tweak the optimizer: by using the
minimize_method,minimize_options, andminimize_kwargskeywords insolve_optimal_trajectory(), you can choose the SciPy optimization function that you use and set many parameters. Seescipy.optimize.minimize()for more information on the optimizers that are available and the options and keywords that they accept.Walk before you run: try setting up a simpler version of the optimization, remove constraints or simplifying the cost to get a simple version of the problem working and then add complexity. Sometimes this can help you find the right set of options or identify situations in which you are being too aggressive in what you are trying to get the system to do.
See Optimal control for vehicle steering (lane change) for some examples of different problem formulations.
Module classes and functions
The following classes and functions are defined in the
optimal module:
|
Description of a finite horizon, optimal control problem. |
|
Result from solving an optimal control problem. |
|
Description of a finite horizon, optimal estimation problem. |
|
Result from solving an optimal estimation problem. |
|
Create a model predictive I/O control system. |
|
Create constraint for bounded disturbances. |
|
Create cost function for Gaussian likelihoods. |
|
Create input constraint from polytope. |
|
Create input constraint from polytope. |
|
Create output constraint from polytope. |
|
Create output constraint from range. |
|
Create quadratic cost function. |
|
Compute the solution to an optimal control problem. |
|
Compute the solution to a finite horizon estimation problem. |
|
Create state constraint from polytope. |
|
Create state constraint from range. |